




Turbinia is an open-source framework for deploying, managing, and running distributed forensic workloads.
It is intended to automate running of common forensic processing suits (i.e. Plaso, TSK, strings, etc) to help with processing evidence in the Cloud, scaling the processing of large amounts of evidence, and decreasing response time by parallelizing processing where possible.
How it works
![]()
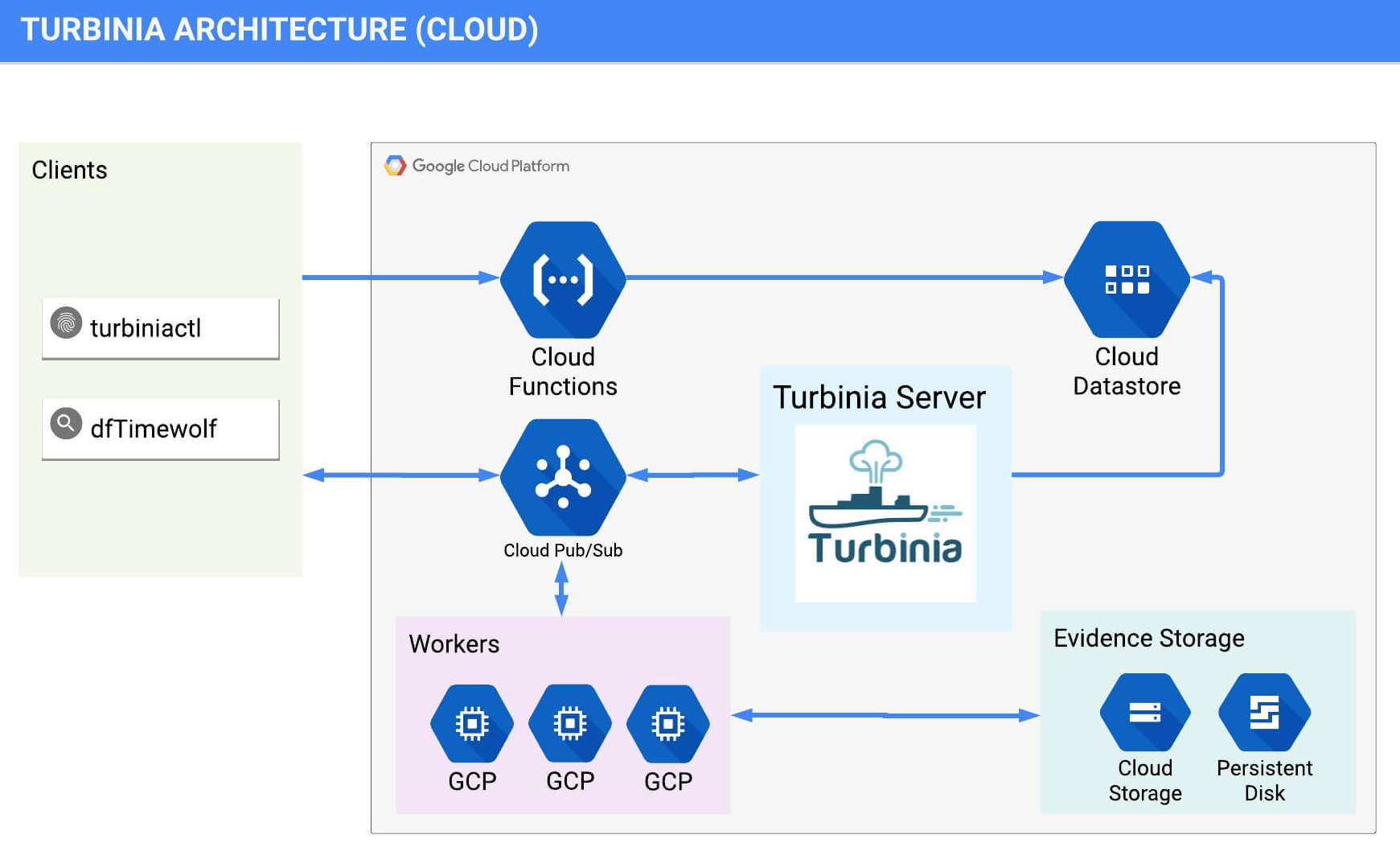
Turbinia is composed of different components for the client, server and the workers. These components can be run in the Cloud, on local machines, or as a hybrid of both. The Turbinia client makes requests to process evidence to the Turbinia server.
The Turbinia server creates logical jobs from these incoming user requests, which creates and schedules forensic processing tasks to be run by the workers.
The evidence to be processed will be split up by the jobs when possible, and many tasks can be created in order to process the evidence in parallel. One or more workers run continuously to process tasks from the server. Any new evidence created or discovered by the tasks will be fed back into Turbinia for further processing.
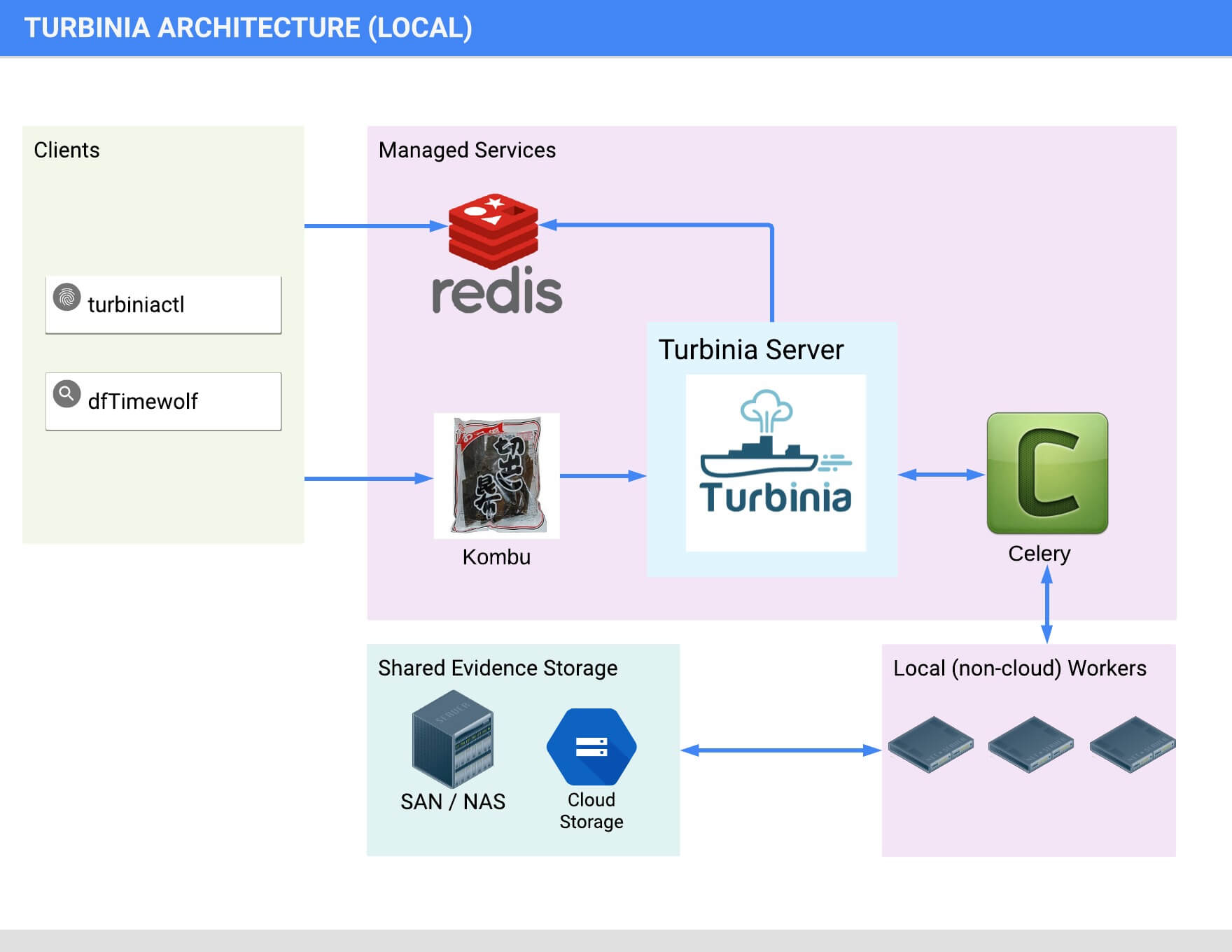
Communication from the client to the server is currently done with either Google Cloud PubSub or Kombu messaging. The worker implementation can use either PSQ (a Google Cloud PubSub Task Queue) or Celery for task scheduling.
Architecture
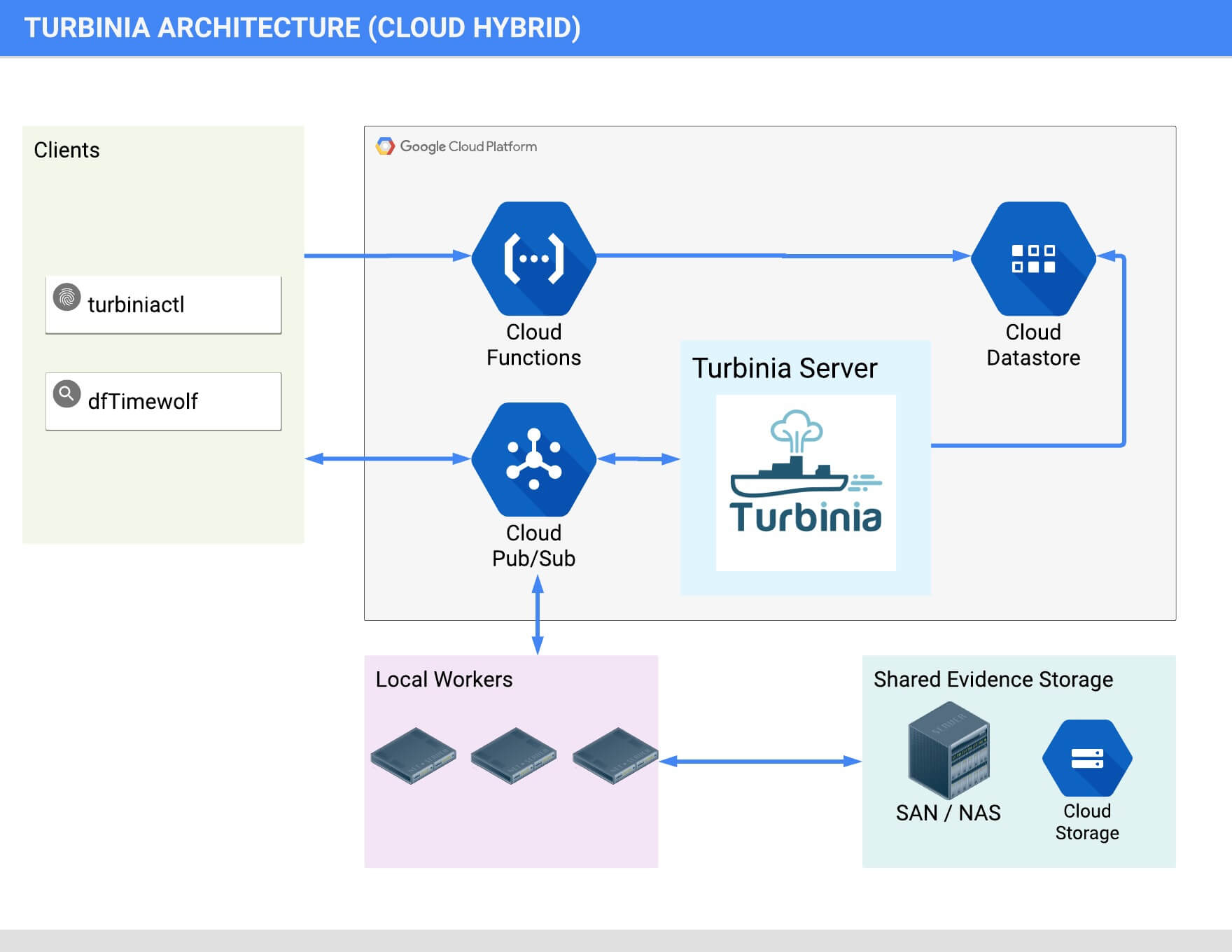
Turbinia can run its components completely in the Cloud, on local machines, or as a hybrid of both. When running in hybrid mode, Turbinia uses Cloud services, but the workers and the Turbinia server run locally. Running locally or in hybrid mode requires shared storage to be accessible by all Workers.
Cloud Architecture
Hybrid Architecture
Local Architecture
More information on Turbinia and how it works can be found here.
Status
Turbinia is currently in Alpha release.
Installation
There is an rough installation guide here.
Usage
The basic steps to get things running after the initial installation and configuration are:
- Start Turbinia server component with turbiniactl server command
- Start one or more Turbinia workers with turbiniactl psqworker
- Send evidence to be processed from the turbinia client with turbiniactl ${evidencetype}
- Check status of running tasks with turbiniactl status
turbiniactl can be used to start the different components, and here is the basic usage:
$ turbiniactl --help
Usage:
turbiniactl [-h] [-q] [-v] [-d] [-a] [-c CONFIG_FILE] [-C RECIPE_CONFIG] [-f] [-o OUTPUT_DIR] [-L LOG_FILE] [-r REQUEST_ID] [-R] [-S] [-V] [-D] [-F FILTER_PATTERNS_FILE] [-j JOBS_WHITELIST] [-J JOBS_BLACKLIST] [-p POLL_INTERVAL] [-t TASK] [-w] <command> ...
optional arguments:
-h, --help: show this help message and exit -q, --quiet: Show minimal output -v, --verbose: Show verbose output -d, --debug: Show debug output -a, --all_fields: Show all task status fields in output -c CONFIG_FILE, --config_file CONFIG_FILE: Load explicit config file. If specified it will ignore config files in other default locations (/etc/turbinia.conf, ~/.turbiniarc, or in paths referenced in environment variable TURBINIA_CONFIG_PATH) -C RECIPE_CONFIG, --recipe_config RECIPE_CONFIG: Recipe configuration data passed in as comma separated key=value pairs (e.g. "-C key=value,otherkey=othervalue"). These will get passed to tasks as evidence config, and will also be written to the metadata.json file for Evidence types that write it -f, --force_evidence: Force evidence processing request in potentially unsafe conditions -o OUTPUT_DIR, --output_dir OUTPUT_DIR: Directory path for output -L LOG_FILE, --log_file LOG_FILE: Log file -r REQUEST_ID, --request_id REQUEST_ID: Create new requests with this Request ID -R, --run_local: Run completely locally without any server or other infrastructure. This can be used to run one-off Tasks to process data locally. -S, --server: Run Turbinia Server indefinitely -V, --version: Show the version -D, --dump_json: Dump JSON output of Turbinia Request instead of sending it -F FILTER_PATTERNS_FILE, --filter_patterns_file FILTER_PATTERNS_FILE: A file containing newline separated string patterns to filter text based evidence files with (in extended grep regex format). This filtered output will be in addition to the complete output -j JOBS_WHITELIST, --jobs_whitelist JOBS_WHITELIST: A whitelist for Jobs that will be allowed to run (in CSV format, no spaces). This will not force them to run if they are not configured to. This is applied both at server start time and when the client makes a processing request. When applied at server start time the change is persistent while the server is running. When applied by the client, it will only affect that processing request. -J JOBS_BLACKLIST, --jobs_blacklist JOBS_BLACKLIST: A blacklist for Jobs we will not allow to run. See --jobs_whitelist help for details on format and when it is applied. -p POLL_INTERVAL, --poll_interval POLL_INTERVAL: Number of seconds to wait between polling for task state info -t TASK, --task: TASK The name of a single Task to run locally (must be used with --run_local. -w, --wait: Wait to exit until all tasks for the given request have completed
Commands:
<command>
rawdisk : Process RawDisk as Evidence
googleclouddisk: Process Google Cloud Persistent Disk as Evidence
googleclouddiskembedded: Process Google Cloud Persistent Disk with an embedded raw disk image as Evidence
directory: Process a directory as Evidence
listjobs: List all available jobs
psqworker: Run PSQ worker
celeryworker: Run Celery worker
status: Get Turbinia Task status
server: Run Turbinia Server
config: Prints out config file
testnotify: Sends test notification
The commands for processing evidence specify the metadata about that evidence for Turbinia to process. By default, when adding new evidence to be processed, turbiniactl will act as a client and send a request to the configured Turbinia server, otherwise if server is specified, it will start up its own Turbinia server process. Here’s the turbiniactl usage for adding a raw disk type of evidence to be processed by Turbinia:
$ ./turbiniactl rawdisk -h usage: turbiniactl rawdisk [-h] -l LOCAL_PATH [-s SOURCE] [-n NAME]
Optional arguments:
-h, --help: show this help message and exit
-l LOCAL_PATH, --local_path LOCAL_PATH: Local path to the evidence
-s SOURCE, --source SOURCE: Description of the source of the evidence
-n NAME, --name: NAME Descriptive name of the evidence
Status information about the requests that are being or have been processed can be viewed with the turbiniactl status command. You can specify the request ID that was generated, or other filters like the username of the requester, or how many days of processing history you want to view. You can also generate statistics and reports (in markdown format) with other flags.
$ turbiniactl status -h usage: turbiniactl status [-h] [-c] [-C] [-d DAYS_HISTORY] [-f] [-r REQUEST_ID] [-p PRIORITY_FILTER] [-R] [-s] [-t TASK_ID] [-u USER]
optional arguments:
-h, --help show this help message and exit
-c, --close_tasks Close tasks based on Request ID or Task ID
-C, --csv When used with --statistics, the output will be in CSV format
-d DAYS_HISTORY, --days_history DAYS_HISTORY Number of days of history to show
-f, --force Gatekeeper for --close_tasks
-r REQUEST_ID, --request_id REQUEST_ID Show tasks with this Request ID
-p PRIORITY_FILTER, --priority_filter PRIORITY_FILTER This sets what report sections are shown in full detail in report output. Any tasks that have set a report_priority value equal to or lower than this setting will be shown in full detail, and tasks with a higher value will only have a summary shown. To see all tasks report output in full detail, set --priority_filter=100
-R, --full_report Generate full markdown report instead of just a summary
-s, --statistics Generate statistics only
-t TASK_ID, --task_id TASK_ID Show task for given Task ID
-u USER, --user USER Show task for given user
Obligatory Fine Print
This is not an official Google product (experimental or otherwise), it is just code that happens to be owned by Google.





